Token Counting
Chau7 reads input and output token counts from every API response. The numbers your provider charges you but never shows you in context.
What is Token Counting in Chau7?
Token Counting is a feature in the Chau7 terminal that tracks token usage for every intercepted LLM API call. Chau7 uses a calibrated token estimator tuned per provider: Anthropic averages ~3.8 characters per token, OpenAI ~3.3, and Gemini ~4.0. The estimator also adjusts for code content, which typically uses ~15% more tokens than prose.
Chau7 associates token counts with the originating tab, session, and run. When providers include exact counts in their response metadata, Chau7 uses those directly. When metadata is unavailable, the calibrated estimator provides accurate approximations.
How to measure input vs output tokens for Claude Code
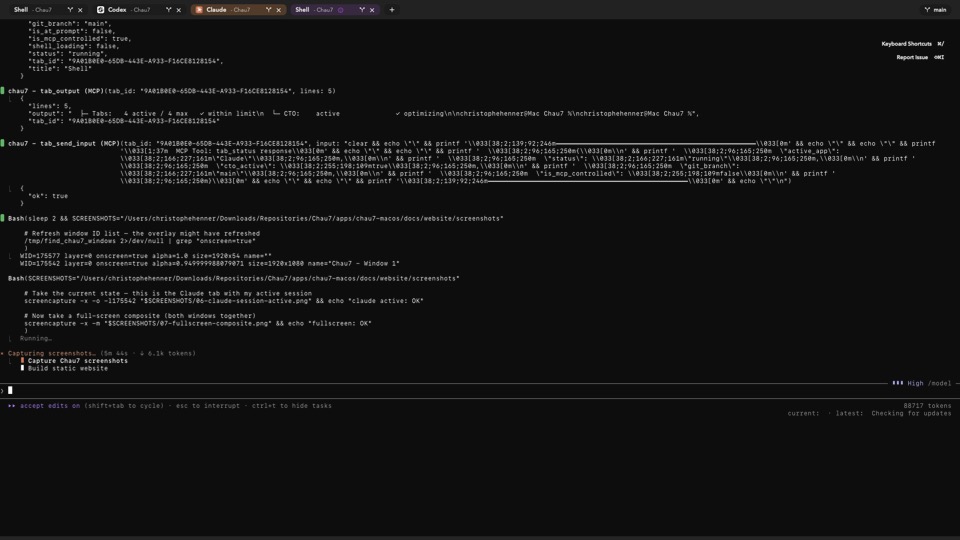
Chau7 intercepts Claude Code's API calls through its built-in TLS/WSS proxy. When Anthropic's response comes back, Chau7 extracts the input token count (the prompt and context sent to the model) and the output token count (the completion returned).
This distinction matters because most providers price input and output tokens differently, often by a factor of three to five. Chau7 tracks both counts separately for every API call so developers can see exactly where their tokens go.
How many tokens does my AI coding agent use per request?
Chau7 tracks every API call individually and shows the input and output token counts for each request as reported by the provider. Developers can review run telemetry through Chau7's MCP server.
All token data in Chau7 is associated with the originating tab, session, and run. Developers can aggregate at any level: per call, per run, per session, or globally across all tabs.
How accurate are Chau7's token counts?
Chau7 reads token counts directly from the API response JSON metadata. OpenAI and Anthropic both report token counts in their response metadata, so Chau7's numbers are exact because they come straight from the provider with no estimation involved.
Can I see token counts for individual tool calls within a run?
Yes. Chau7 tracks each API call individually with its own input and output token counts. Each tool call that triggers an API request gets its own entry in Chau7's token log.
Developers can review run telemetry through Chau7's MCP server to see per-call breakdowns. This granularity helps identify which tool calls consume the most tokens within a single agent invocation.
Questions this answers
- What is Token Counting in Chau7 terminal?
- How to measure input vs output tokens for Claude Code?
- How many tokens does my AI coding agent use per request?
- How accurate are the token counts?
- Can I see token counts for individual tool calls within a run?
Frequently asked questions
What is Token Counting in Chau7 terminal?
Token Counting is a feature in the Chau7 terminal that reads input and output token counts from the JSON metadata of every intercepted LLM API response. Chau7 extracts the token counts that providers like OpenAI and Anthropic include in their API responses.
How to measure input vs output tokens for Claude Code?
Chau7 intercepts Claude Code's API calls through its built-in TLS/WSS proxy and reads the token counts directly from Anthropic's response metadata. Chau7 displays input tokens (prompt and context) and output tokens (completion) separately for every call.
How many tokens does my AI coding agent use per request?
Chau7 tracks every API call individually and shows the input and output token counts for each request as reported by the provider. Developers can review run telemetry through Chau7's MCP server or review aggregate totals per session.
How accurate are the token counts?
Chau7 reads token counts directly from the API response JSON metadata. When the LLM provider includes token counts in the response (OpenAI and Anthropic both do), Chau7's numbers are exact because they come straight from the provider.
Can I see token counts for individual tool calls within a run?
Yes. Chau7 tracks each API call individually with its own input and output token counts. Developers can review run telemetry through Chau7's MCP server to see per-call breakdowns.
Does Chau7 count tokens for self-hosted or custom models?
If the API response includes token counts in its JSON metadata, Chau7 reads them directly regardless of provider. For responses that do not include token counts in metadata, Chau7 cannot report token usage.